scrapy 介绍 scrapy 是一个基于 Python 语言的爬虫框架。有了框架的存在,我们可以更方便的爬虫了,框架帮我们封装好了下载等模块,而且更重要的是框架使用了异步的模式,加快了爬虫的速度。
环境搭建 在命令行中执行 conda install Scrapy 这样就安装好了 Scrapy 模块,是不是特别简单。ahahahha
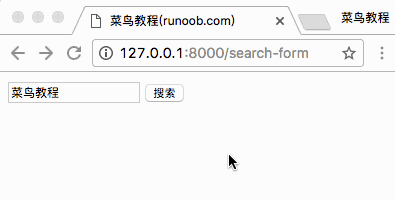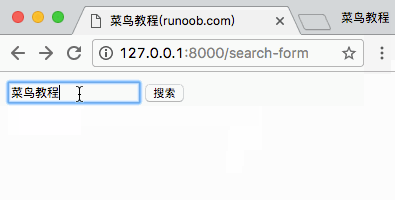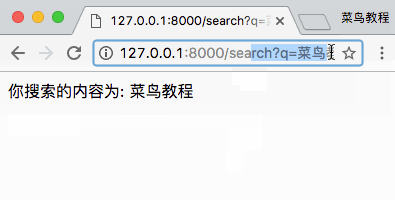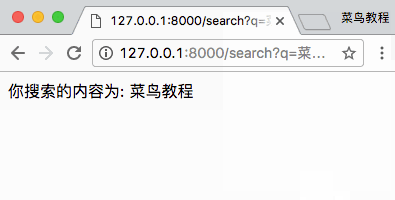
开始 接下来就要开始我们的 scrapy 之路了。
新建项目 使用 Scrapy 第一步:创建项目,命令行进入你需要放置项目的目录,然后执行
scrapy startproject ScrapyDemo #ScrapyDemo是项目名称
目录结构 这时会在目录下多出一个 ScrapyDemo 文件夹,这就是 Scrapy 项目了,项目的结构如下1 2 3 4 5 6 7 8 9 10 11 . |-- ScrapyDemo | `-- ScrapyDemo | |-- spiders | | `-- __init__.py | |-- __init__.py | |-- items.py | |-- middlewares.py | |-- pipelines.py | `-- settings.py `-- scrapy.cfg
目录说明:
ScrapyDemo(外层) 项目总目录
ScrapyDemo(内层) 项目目录
scrapy.cfg 项目的配置文件
spiders 放置我们的爬虫代码的目录
items.py 定义我们需要获取的字段
middlewares.py
pipelines.py 用来定义存储
settings.py 项目设置文件
还有一点要注意的是,Scrapy 默认是不能在 IDE 中调试的,所以要在项目总目录下新建一个 entrypoint.py 文件,写下以下内容:1 2 3 4 from scrapy.cmdline import executeexecute(['scrapy' , 'crawl' , 'dingdian' ])
现在整个目录应该是这样(盗图..)
架构 下面我们先来看一下框架的架构图
Scrapy Engine: 这是引擎,负责Spiders、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等等!(像不像人的身体?)
Scheduler(调度器): 它负责接受引擎发送过来的requests请求,并按照一定的方式进行整理排列,入队、并等待Scrapy Engine(引擎)来请求时,交给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spiders来处理,
Spiders:它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline:它负责处理Spiders中获取到的Item,并进行处理,比如去重,持久化存储(存数据库,写入文件,总之就是保存数据用的)
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spiders中间‘通信’的功能组件(比如进入Spiders的Responses;和从Spiders出去的Requests)
数据在整个Scrapy的流向:
程序运行的时候,
引擎:Hi!Spider, 你要处理哪一个网站?
Spiders:我要处理23wx.com
引擎:你把第一个需要的处理的URL给我吧。
Spiders:给你第一个URL是XXXXXXX.com
引擎:Hi!调度器,我这有request你帮我排序入队一下。
调度器:好的,正在处理你等一下。
引擎:Hi!调度器,把你处理好的request给我,
调度器:给你,这是我处理好的request
引擎:Hi!下载器,你按照下载中间件的设置帮我下载一下这个request
下载器:好的!给你,这是下载好的东西。(如果失败:不好意思,这个request下载失败,然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载。)
引擎:Hi!Spiders,这是下载好的东西,并且已经按照Spider中间件处理过了,你处理一下(注意!这儿responses默认是交给def parse这个函数处理的)
Spiders:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,这是我需要跟进的URL,将它的responses交给函数 def xxxx(self, responses)处理。还有这是我获取到的Item。
引擎:Hi !Item Pipeline 我这儿有个item你帮我处理一下!调度器!这是我需要的URL你帮我处理下。然后从第四步开始循环,直到获取到你需要的信息,
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的 URL,Scrapy会重新下载。)
写代码 建立一个项目之后:
第一件事就是在 items.py 文件中定义我们需要的字段,用来临时存储要保存的数据,方便以后数据的持久化存储,比如 数据库 文本文件等。
第二件事是在 spiders.py 中编写自己的爬虫代码
第三件事是在 pipelines.py 中存储自己的数据
建议:在大家调试的时候在settings.py中取消下面几行的注释: 1 2 3 4 5 HTTPCACHE_ENABLED = True HTTPCACHE_EXPIRATION_SECS = 0 HTTPCACHE_DIR = 'httpcache' HTTPCACHE_IGNORE_HTTP_CODES = [] HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
上面代码的作用是 Scrapy 会缓存你有的 Requests! 当你再次请求时,如果存在缓存文档则返回缓存文档,而不是去网站请求,这样既加快了本地调试速度,也减轻了 网站的压力。一举多得
定义字段 要根据自己要爬取的内容来定义字段。比如,在这里我们要爬的是小说站点就需要定义,小说名字,作者,小说地址,连载状态,字数,文章类别 等字段。
就像下面这样:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class ScrapydemoItem (scrapy.Item) : name = scrapy.Field() author = scrapy.Field() novelurl = scrapy.Field() serialstatus = scrapy.Field() serialnumber = scrapy.Field() category = scrapy.Field() novel_id = scrapy.Field()
编写 spider 在 spiders 目录下新建一个 ScrapyDemo.py 文件,并导入我们需用的模块
1 2 3 4 5 6 7 import scrapy import refrom bs4 import BeautifulSoupfrom scrapy.http import Requestfrom ScrapyDemo.items import ScrapydemoItemclass Muspider (scrapy.Spider) :
我们需要从一个地址入手开始爬取,我在顶点小说上没有发现有全站小说地址,但是我找到每个分类地址全部小说:
玄幻魔幻:http://www.x23us.com/class/1_1.html
武侠修真:http://www.x23us.com/class/2_1.html
都市言情:http://www.x23us.com/class/3_1.html
历史军事:http://www.x23us.com/class/4_1.html
侦探推理:http://www.x23us.com/class/5_1.html
网游动漫:http://www.x23us.com/class/6_1.html
科幻小说:http://www.x23us.com/class/7_1.html
恐怖灵异:http://www.x23us.com/class/8_1.html
散文诗词:http://www.x23us.com/class/9_1.html
其他:http://www.x23us.com/class/10_1.html
全本:http://www.x23us.com/quanben/1
好啦!入口地址我们找到了,现在开始写第一部分代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import scrapyimport refrom bs4 import BeautifulSoupfrom scrapy.http import Requestfrom ScrapyDemo.items import ScrapydemoItemclass Myspider (scrapy.Spider) : name = 'ScrapyDemo' allowed_domains = ['x23us.com' ] bash_url = 'http://www.x23us.com/class/' bashurl = '.html' def start_requests (self) : for i in range(1 , 11 ): url = self.bash_url + str(i) + '_1' + self.bashurl yield Request(url,self.parse) def parse (self, response) : print(response.text)
首先我们创建一个类 Myspider;这个类继承自 scrapy.Spider
定义了一个 allowed_domains ;这个不是必须的;但是在某写情况下需要用得到,比如使用爬取规则的时候就需要了;它的作用是只会跟进存在于 allowed_domains 中的 URL。不存在的 URL 会被忽略。
第九行定义的 name 是之前我们在 entrypoint.py 文件中的第三个参数 此 name 在整个项目中有且只能有一个、名字不可重复!!!
之后可以运行 entrypoint.py 文件来检查一下代码时候可以正常工作。
请求就这么轻而易举的实现了啊!简直So Easy!
继续 继续!
我们需要历遍所有页面才能取得所有的小说页面连接:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import scrapyimport refrom bs4 import BeautifulSoupfrom scrapy.http import Requestfrom ScrapyDemo.items import ScrapydemoItemclass Muspider (scrapy.Spider) : name = 'ScrapyDemo' allowed_domains = ['x23us.com' ] bash_url = 'http://www.x23us.com/class/' bashurl = '.html' def start_requests (self) : for i in range(1 , 11 ): url = self.bash_url + str(i) + '_1' + self.bashurl yield Request(url, self.parse) def parse (self, response) : max_span = BeautifulSoup(response.text, 'lxml' ).find('div' , class_='pagelink' ).find_all('a' )[-1 ].get_text() bashurl = str(response.url)[:-6 ] for num in range(1 , int(max_span) + 1 ): url = bashurl + str(num) + self.bashurl yield Request(url, self.get_name) def get_name (self, response) : novels = BeautifulSoup(str(response), 'lxml' ).find_all('tr' , bgcolor='#F2F2F2' ) for navel in novels: a = navel.find('a' ) name = a['title' ] url = a['href' ] yield Request(url, callback=self.get_chapterurl, meta={'name' : name, 'url' : url}) def get_chapterurl (self, response) : item = ScrapydemoItem() item['name' ] = str(response.meta['name' ]).replace('\xa0' , '' ) item['novelurl' ] = response.meta['url' ] category = BeautifulSoup(response.text, 'lxml' ).find('table' ).find('a' ).get_text() author = BeautifulSoup(response.text, 'lxml' ).find('table' ).find_all('td' )[1 ].get_text() bash_url = BeautifulSoup(response.text, 'lxml' ).find('p' , class_='btnlinks' ).find('a' , class_='read' )['href' ] name_id = str(bash_url)[-6 :-1 ].replace('/' , '' ) item['category' ] = str(category).replace('/' , '' ) item['author' ] = str(author).replace('/' , '' ) item['name_id' ] = name_id return item
自定义 Pipeline 做一个自定义的MySQL的Pipeline。首先为了能好区分框架自带的Pipeline,我们把MySQL的Pipeline单独放到一个目录里面。
pipelines.py 这个是我们写存放数据的文件
sql.py 看名字就知道,需要的sql语句。
首先是需要的 MySQL 表,1 2 3 4 5 6 7 8 9 DROP TABLE IF EXISTS `dd_name` ;CREATE TABLE `dd_name` ( `id` int (11 ) NOT NULL AUTO_INCREMENT, `xs_name` varchar (255 ) DEFAULT NULL , `xs_author` varchar (255 ) DEFAULT NULL , `category` varchar (255 ) DEFAULT NULL , `name_id` varchar (255 ) DEFAULT NULL , PRIMARY KEY (`id` ) ) ENGINE =InnoDB AUTO_INCREMENT=38 DEFAULT CHARSET =utf8mb4;
记得在 settings.py 文件中定义好 MySQL 的配置文件1 2 3 4 5 MYSQL_HOSTS = '127.0.0.1' MYSQL_USER = 'root' MYSQL_PORT = '3306' MYSQL_PASSWORD = '****' MYSQL_DB = 'xiaoshuo'
在开始写sql.py之前,我们需要安装一个Python操作MySQL的包,来自MySQL官方的一个包:点我下载
下载完成后解压出来,从 cmd 进入该目录的绝对路径,然后 python setup.py install ;即可完成安装(记得以管理员身份打开命令行)
sql.py1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import mysql.connectorfrom ScrapyDemo import settingsMYSQL_USER = settings.MYSQL_USER MYSQL_PASSWORD = settings.MYSQL_PASSWORD MYSQL_HOST = settings.MYSQL_HOSTS MYSQL_PORT = settings.MYSQL_PORT MYSQL_DB = settings.MYSQL_DB cnx = mysql.connector.connect(user=MYSQL_USER, password=MYSQL_PASSWORD, host=MYSQL_HOST, database=MYSQL_DB) cur = cnx.cursor(buffered=True ) class Sql : @classmethod def insert_dd_name (cls, xs_name, xs_author, category, name_id) : sql = 'INSERT INTO dd_name (`xs_name`,`xs_author`,`category`,``name_id) VALUES (%(xs_name)s,%(xs_author)s,,%(category)s,,%(name_id)s)' VALUE = { 'xs_name' : xs_name, 'xs_author' : xs_author, 'category' : category, 'name_id' : name_id } cur.execute(sql, VALUE) cnx.commit() @classmethod def select_name (cls, name_id) : sql = 'SELECT EXISTS(SELECT 1 FROM dd_name WHERE name_id=%(name_id)s)' value = { 'name_id' : name_id } cur.execute(sql, value) cnx.commit()
来开始写pipeline1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from ScrapyDemo.items import ScrapydemoItemfrom .sql import Sqlclass ScrapyPipeline (object) : def process_item (self, item, sqider) : if isinstance(item, ScrapydemoItem): name_id = item['name_id' ] ret = Sql.select_name(name_id) if ret[0 ] == 1 : print('已经存在了' ) pass else : xs_name = item['xs_name' ] xs_author = item['xs_author' ] category = item['category' ] Sql.insert_dd_name(xs_name, xs_author, category, name_id) print('开始存小说标题' )
定义了一个process_item函数并有,item和spider这两个参数(请注意啊!这两玩意儿 务必!!!要加上!!千万不能少!!!!务必!!!务必!!! )
搞完!下面我们启用这个Pipeline在settings中作如下设置:
后面的 1 是优先级程度(1-1000随意设置,数值越低,组件的优先级越高)
下面我们开始还剩下的一些内容获取:小说章节 和章节内容
首先我们在 item.py 中新定义一些需要获取内容的字段:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import scrapyclass ScrapydemoItem (scrapy.Item) : name = scrapy.Field() author = scrapy.Field() novelurl = scrapy.Field() serialstatus = scrapy.Field() serialnumber = scrapy.Field() category = scrapy.Field() novel_id = scrapy.Field() class Content (scrapy.Item) : id_name = scrapy.Field() chaptercontent = scrapy.Field() num = scrapy.Field() chapter_url = scrapy.Field() chapter_name = scrapy.Field()
继续编写Spider文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 def get_chapterurl (self, response) : item = ScrapydemoItem() item['name' ] = str(response.meta['name' ]).replace('\xa0' , '' ) item['novelurl' ] = response.meta['url' ] category = BeautifulSoup(response.text, 'lxml' ).find('table' ).find('a' ).get_text() author = BeautifulSoup(response.text, 'lxml' ).find('table' ).find_all('td' )[1 ].get_text() bash_url = BeautifulSoup(response.text, 'lxml' ).find('p' , class_='btnlinks' ).find('a' , class_='read' )['href' ] name_id = str(bash_url)[-6 :-1 ].replace('/' , '' ) item['category' ] = str(category).replace('/' , '' ) item['author' ] = str(author).replace('/' , '' ) item['name_id' ] = name_id yield item yield Request(bash_url, callback=self.get_chapter, meta={'name_id' : name_id}) def get_chapter (self, response) : urls = re.findall(r'<td class="L"><a href="(.*?)">(.*?)</a></td>' , response.text) num = 0 for url in urls: num = num + 1 chapterurl = response.url + url[0 ] chaptername = url[1 ] yield Request(chapterurl, callback=self.get_chaptercontent, meta={ 'num' : num, 'name_id' : response.meta['name_id' ], 'chapter_url' : chapterurl, 'chaptername' : chaptername }) def get_chaptercontent (self, response) : item = Content() item['id_name' ] = response.meta['name_id' ] item['num' ] = response.meta['num' ] item['chapter_url' ] = response.meta['chapter_url' ] item['chapter_name' ] = response.meta['chaptername' ] content = BeautifulSoup(response.text, 'lxml' ).find('dd' , id='contents' ).get_text() item['content' ] = str(content).replace('\xa0' , '' ) return item
注意 13\14 行,这个地方返回item是不能用return的哦!用了就结束了,程序就不会继续下去了,得用 yield
下面我们来写存储这部分spider的Pipeline:
数据表:1 2 3 4 5 6 7 8 9 10 11 DROP TABLE IF EXISTS `dd_chaptername` ;CREATE TABLE `dd_chaptername` ( `id` int (11 ) NOT NULL AUTO_INCREMENT, `xs_chaptername` varchar (255 ) DEFAULT NULL , `xs_content` text , `id_name` int (11 ) DEFAULT NULL , `num_id` int (11 ) DEFAULT NULL , `url` varchar (255 ) DEFAULT NULL , PRIMARY KEY (`id` ) ) ENGINE =InnoDB AUTO_INCREMENT=2726 DEFAULT CHARSET =gb18030; SET FOREIGN_KEY_CHECKS=1 ;
下面是Pipeline:
有小伙伴注意,这儿比上面一个Pipeline少一个判断,因为我把判断移动到Spider中去了,这样就可以减少一次Request,减轻服务器压力。
改变后的Spider长这样: